读了三篇论文:
Functional Pearls: A Poor Man’s Concurrency Monad: 用continuation交替执行多个“进程”实现并发,只是一种模拟,实际上只有一个进程。然后通过monad transfermer可以为任意的Monad增加并发功能。第一次读的时候比较疑惑,因为他说思想是把任意monad的原子操作提升到concurrency monad。我看了第二篇论文再回来看就明白了。
Combining events and threads for scalable network services: 在第一篇的基础上,使用多个线程实现。event-driven高效但复杂,thread相对简单,这篇论文是结合了event-driven和thread这两种模型,底层是event-driven,但是可以向上提供线程的接口。
Scalable I/O Event Handling for GHC: 在第二篇的基础上,整合进GHC,用里面的话说就是让所以Haskell程序(员)都受益了。
我觉得1的核心思想有两个:
- 用一个代数数据类型(ADT)表示程序的执行以及可执行的操作
- 用continuation构造上面所说的ADT, 通过continuation monad提供友好的接口。
在Scheme可以用call/cc操作continuation,直接就可以模拟并发,很强大也很命令式。构造ADT的这种方法不需用call/cc,只能在ADT的节点调度,但是实现简单,陷阱少,也更好理解。(试过用Scheme实现coroutine,一小心就保存错continuation…)
假设一个程序可以输出Ping和Pong,那就可以用下面这一个ADT表示(增加了End表示结束):
data PP = Ping PP
| Pong PP
| End一个输出两个Pong再一个Ping的程序表示成:
prog = Pong (Pong (Ping End))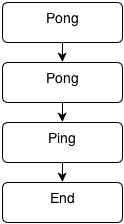
一个不断交替输出Ping和Pong的程序就可以表示为:
pploop = Ping (Pong pploop)
也就是说一个程序表示成一个图,实际的执行就是遍历这个图,根据每个节点执行相应操作。
在这基础上实现“进程”就很简单了,这样增加树的分叉就行了。
data PP = Ping PP
| Pong PP
| Fork PP PP
| End更现在一个不断交替输出Ping和Pong的程序就可以表示为:
ppfork = let p1 = Ping p1
p2 = Pong p2
in Fork p1 p2
虽然这是一个无穷的数据结构,但是Haskell只会在需要的时候才构造,而访问过的节点可以被GC1(用ghc编译,ppfork执行很久都没问题,而且内存不涨,Hugs瞬间GC失败,runghc内存狂涨)。
然后就可以增加占有线程(Hold)、主动放弃进程(Yield)、结束整个程序(Exit)的操作,甚至可以执行一些IO操作(IOAction):
data PP = Ping PP
| Pong PP
| Fork PP PP
| End
| Exit
| Yield PP
| Hold PP
| IOAction (IO ()) PP轮转部分对应的调度器可以这样实现(RR表示round robin):
runRR :: [PP] -> IO ()
runRR [] = return ()
runRR (p:ps) =
case p of
Ping p1 -> putStrLn "Ping" >> runRR (ps ++ [p1])
Pong p1 -> putStrLn "Pong" >> runRR (ps ++ [p1])
Fork p1 p2 -> putStrLn "Fork" >> runRR (ps ++ [p1, p2])
End -> putStrLn "End" >> runRR ps
Exit -> putStrLn "Exit"
Yield p1 -> putStrLn "Yield" >> runRR (ps ++ [p1])
Hold p1 -> putStrLn "Hold" >> runCO (p1:ps)
IOAction act p1 -> act >> runRR (ps ++ [p1])当一个进程执行Hold之后就转到runCO:
runCO :: [PP] -> IO ()
runCO [] = return ()
runCO (p:ps) =
case p of
Ping p1 -> putStrLn "Ping" >> runCO (p1:ps)
Pong p1 -> putStrLn "Pong" >> runCO (p1:ps)
Fork p1 p2 -> putStrLn "Fork" >> runCO (p1:p2:ps)
End -> putStrLn "End" >> runCO ps
Exit -> putStrLn "Exit"
Yield p1 -> putStrLn "Yield" >> runRR (ps ++ [p1])
Hold p1 -> putStrLn "Hold" >> runCO (p1:ps)
IOAction act p1 -> act >> runCO (p1:ps)到这里也就可以明白为什么第一篇论文说“任意monad的原子操作提升到concurrency monad”了。因为在遍历这课树的时候是以节点为单位的,而提升进来的操作都是树的一个节点,例如上面的IOAction就可以看做把IO monad里的操作提升进来。
到目前为止一切都还好,只是:
- 直接构造那个ADT有点麻烦
- IOAction不能返回结果
- 只能在IO Monad里运行
放心,在下一部分我们会把问题会被各个击破的。
这个图画错了,应该是类似上面一张图那样,两个分支都是对自身的循环引用,所以是不需GC的了。↩